In my previous work, we discussed different ideas and ways in writing a server. To quickly recap, it’s writing it asychronously, writing a multi-threaded server or writing a “dumb” one. Each one has its pros and cons. People might say writing an async server would solve issues but it would not be the complete story. An async server helps when threads are idle waiting on I/O — network reads, file reads from external devices. Things like this, you can build an async server and it’ll get you the fastest latency. But they don’t provide us with the same improvements when the work is not I/O bound. Forge’s threads are idle waiting on compute — a different problem. We’ll see why in this article.
To recap you can also checkout my prev post on optimizing a server.
Today we’ll talk about Forge.
this article will cover things like technical decisions, problems I faced while writing the code etc
Forge: overview
It is a multi-threaded server implementation in C++.
It has the following components:
- Server
- Scheduler
- Llama.cpp backend This is the high level view.
What forge does in one sentence: “accepts HTTP POST requests at /infer with a JSON body containing a query, runs inference on a local GGUF model, and returns the result. Also exposes /metrics returning queue depth and p99 latency.”
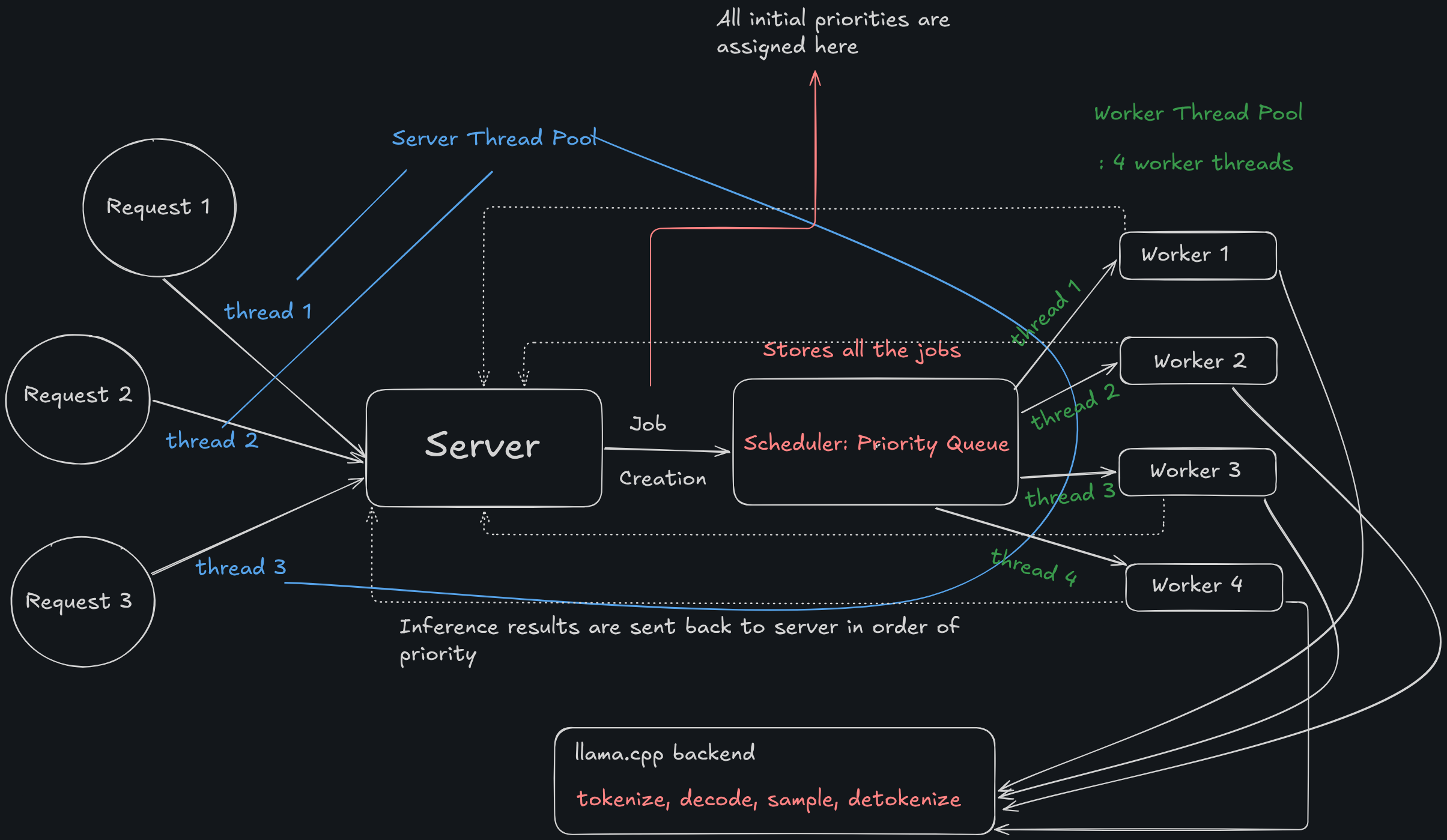
I am pretty sure that simple looking working diagram made you understand the whole project by itself but even if it didn’t, I’ll walk you through what this is.
The idea is we’ve got client requesting on our server. We have a server. How do we efficiently design a system where we can inference on a shared backend like llama.cpp with MINIMUM bottlenecks?
This is how I did it in Forge
Job
A job is a just a dataclass sort of thing (in c++ its just a struct) that gives order to our data.
Some important information that it holds is:
- ID: request ID.
- Query: query from the client
- currPriority: one of the most important aspects of this dataclass.
- startTime: when was the request recieved?
Scheduler
Scheduler is a class designed to hold a bunch of jobs.
Scheduler is a priority-queue based system that holds data in order of their currPriority.
In my system; 1-> normal and 2-> urgent.
These are the two initial priority.
One test case that we should think about is: what happens if there are 20 urgent requests and 1 normal/batch request? How do we handle that?
This is where we talk about the starvation problem
Starvation and aging
To handle issues like starvation where all the “urgent jobs” are processed, what are we doing with the normal jobs?
To deal with this we do aging.
The idea is: after sometime, we update the priorities of these normal jobs so that after sometime they become a priority and are processed.
In forge, you can set the aging_rate which is by default at 0.2. It is a unitless priority increment.
So for example at t = 2 a job came with initial priority 1. The aging thread runs every second, so after 5 seconds, currPriority = 1 + (5 * 0.2) = 2. Urgent job.
Aging_thread
We implement this by creating a thread when we init the scheduler and make it do:
- every second, go to each job in the queue, and update their currPriority
Worker
This is a thread. You can create n workers. We create 4 workers in forge by default. The work of these is to take the top job from the scheduler and get results back to server.
This is the part of the code where llama.cpp is connects.
It has:
- run() method: takes the job from scheduler and gives to runInference() method
- runInference() method: does the inference, waits till gets result back and sends the response to server.
Now maybe we can look at the image above and make sense of it.
Each request is being sent to the Scheduler as a job.
When we init scheduler, the aging_thread begins and ends only when the scheduler is destroyed.
Each request is picked up by a thread whose job is to take requests from clients -> give it to server -> get response from the server and give to client. These are the server threads in the diagram colored in blue.
Now, there are worker threads (marked in green). Each of them are supposed to take the job from the scheduler and get result from the llama backend. They wait until the inference is complete at the llama.cpp backend only and only come with a response, unlike an async server.
This causes some bottlenecks. We will discuss about the bottlenecks of this project in the end.
Each worker then gets the response to server where the slept server-threads are told to give these back to the clients.
Let’s talk about the implementation details of this project.
implementation details and notes
I chose to implement this in C++ because:
- its fast
- its cool
- i know it
- i dont know rust
- its cool But before diving into code, let’s talk about THREADS.
Threads
The whole program is filled with threads actually.
This is what confused me the most and i spent the most time here.
So, there are 3 thread pools:
- Server thread pool: N threads for N requests but short lived - only lives until the connection is there
- Scheduler: there’s 1 thread that’s for aging
- Worker thread pool: n=4 threads for PROCESSING top jobs from the scheduler This was basically a design choice, you could also design the system any other way, I chose to do it this way.
We noticed in the previous article that one major issue/bottleneck is WHAT the thread is doing while the request is being processed. To handle that we use two very interesting C++ primitives:
- Condition variable
- Promise/future
- Condition variable: the threads wait for a state change, not a speicific value / target. In forge, what happens when the scheduler’s queue is empty? We wait for a condition variable.
- Promise/future: Communication between threads. One thread promises another that “I’ll get you A value”. In forge, the server threads create a promise and the worker thread, when the inference is done do
promise.set_value(RESULT_FROM_INFERENCE);and boom, the server thread wakes up with a result in their hand.
This was the most complicated thing to visualize, for me. You might get it intuitively by imagining a lot threads in your head.
Let’s talk about the other implementation stuff now.
Job code
I started with writing the Job struct. It’s as simple as it gets.
struct Job {
int id; // good for logging, not required for minimal
std::string query;
std::chrono::steady_clock::time_point startTime;
int currPriority = 1;
int initPriority = 1;
std::shared_ptr<std::promise<std::string>> p;
};
what would happen if we didn’t have shared_ptr in there?
The job gets moved into the scheduler. The handler no longer has the job. But the promise is a shared_ptr, so the handler grabbed a reference to it before the move — via job->p->get_future(). Now two things reference the same promise object: the job (worker side) and the future (handler side).
shared_ptr ensures the promise object stays alive until both sides are done with it. That’s it.
scheduler code
The scheduler has 3-4 major methods.
- Enque -> add job to the queue
void enque(std::unique_ptr<Job> job) {
std::lock_guard<std::mutex> lock(m);
q.push(std::move(job));
cv.notify_one();
}
- deque_locked -> remove the top job and return a unique_ptr to it
std::unique_ptr<Job> deque_locked() {
if (q.empty()) {
return nullptr;
} else {
std::unique_ptr<Job> temp = std::move(const_cast<std::unique_ptr<Job>&>(q.top()));
q.pop();
return temp;
}
}
- aging_loop -> the aging thread starts at the initialization of the scheduler and continues till the destruction of scheduler
void aging_loop () {
while(!shutdown) {
std::this_thread::sleep_for(std::chrono::seconds(1));
std::vector<std::unique_ptr<Job>> t;
{
std::lock_guard<std::mutex> lock(m);
while (!q.empty()) {
t.push_back(std::move(const_cast<std::unique_ptr<Job>&>(q.top())));
q.pop();
}
for (auto& i : t) {
i->currPriority += aging_rate;
q.push(std::move(i));
}
}
if (!t.empty()) cv.notify_all();
}
}
- size -> to return the length of the queue at any given moment
size_t size() {
std::lock_guard<std::mutex> lock(m);
return q.size();
}
- Since we want to tell the priority queue to compare on
currPriority, we create a custom comparator method.
struct JobComparator {
bool operator()(const std::unique_ptr<Job>& a, const std::unique_ptr<Job>& b) {
return a->currPriority < b->currPriority;
}
};
// and at initialization we do
std::priority_queue<std::unique_ptr<Job>, std::vector<std::unique_ptr<Job>>, JobComparator> q;
btw look at this beautiful piece of code:
t.push_back(std::move(const_cast<std::unique_ptr<Job>&>(q.top())));
worker code
Now here’s where the code gets a little lengthy but the idea really is simple.
It has two main methods:
- run(): take the query from the job and give it to
runInference()
void run () {
// thread takes the job from scheduler and gives it to runINference method which then computes result
while (true) {
std::unique_lock<std::mutex> lock(sch.m);
sch.cv.wait(lock, [this] {return !sch.q.empty() || sch.shutdown;}); // make the thread wake up exactly when a job comes.
if (sch.shutdown && sch.q.empty()) break;
std::unique_ptr<Job> job = sch.deque_locked();
lock.unlock();
if (job) {
std::string result = runInference(job->query);
job->p->set_value(result);
auto latency = (float)std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now() - job->startTime
).count();
std::lock_guard<std::mutex> lock_metrics(sch.m);
sch.latencies.push_back(latency);
}
}
}
- runInference(): from llama.cpp, get a response back and store it in
result
std::string runInference (const std::string& prompt) {
llama_memory_clear(llama_get_memory(context), true);
std::string result;
// 1. tokenize
// first call to get size
int n_tokens = llama_tokenize(vocab, prompt.c_str(), prompt.size(), NULL, 0, true, true);
std::vector<llama_token> prompt_tokens (std::abs(n_tokens));
n_tokens = llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), true, true);
if (n_tokens < 0) {
prompt_tokens.resize(-n_tokens);
llama_tokenize(vocab, prompt.c_str(), prompt.size(), prompt_tokens.data(), prompt_tokens.size(), true, true);
}
// sampler : decides out of the batch of possible probabilities which token to choose
// has greedy, and temperature... we will do greedy
auto sparams = llama_sampler_chain_default_params();
sparams.no_perf = false;
llama_sampler* smpl = llama_sampler_chain_init(sparams);
llama_sampler_chain_add(smpl, llama_sampler_init_greedy());
// 2. create batch
llama_batch batch = llama_batch_get_one(prompt_tokens.data(), prompt_tokens.size());
// 3. look: decode, sample next token, detokenize append to result, check eog
int n_decode = 0;
llama_token new_token_id;
for (int n_pos =0; n_pos + batch.n_tokens < (int)prompt_tokens.size() + n_predict;) {
// evaluate current batch with transformer
if (llama_decode(context, batch) != 0) break;
n_pos += batch.n_tokens;
// sample next tokens
{
new_token_id = llama_sampler_sample(smpl, context, -1);
// end of generation
if (llama_vocab_is_eog(vocab, new_token_id)) {
break;
}
char buf[128];
int n = llama_token_to_piece(vocab, new_token_id, buf, sizeof(buf), 0, true);
std::string s(buf, n);
result += s;
printf("%s", s.c_str());
fflush(stdout);
// prepare the next batch with the sampled token
batch = llama_batch_get_one(&new_token_id, 1);
n_decode += 1;
}
}
// 4. return result string
llama_sampler_free(smpl);
return result;
}
A lot of this code is from https://github.com/ggml-org/llama.cpp/blob/master/examples/simple/simple.cpp
We just have to focus on what llama.cpp has:
- A model
- context: which is different for each worker (why?)
- sampler
- batch
runInference() gets us a result.
server code
One method is the start(). It just is boilerplate so we’ll skip that but you can look at the code here.
It has other two main methods. It uses sys/socket.h header for the socket connection.
handleClient(): takes the request, makes a job, puts on scheduler, waits onfuture.get()-> gets response from worker, sends to the client. If the request is pointing to `/metrics/ -> call handleMetrics() method.
void handleClient(int client_fd) {
char buf[4096] = {0};
int bytes = recv(client_fd, buf, sizeof(buf), 0);
if (bytes < 0) { close(client_fd); return; }
std::string request(buf, bytes);
if (request.find("GET /metrics") != std::string::npos) {
handleMetrics(client_fd);
return;
}
if (request.find("POST /infer") != std::string::npos) {
size_t pos = request.find("\r\n\r\n");
if (pos == std::string::npos) { close(client_fd); return; }
std::string body = request.substr(pos + 4);
auto j = nlohmann::json::parse(body);
std::string query = j["query"];
auto job = std::make_unique<Job>();
job->query = query;
job->p = std::make_shared<std::promise<std::string>>();
job->startTime = std::chrono::steady_clock::now();
auto future = job->p->get_future();
sch.enque(std::move(job));
std::string result = future.get(); // ---- waiting starts... and ends...
nlohmann::json resp;
resp["response"] = result;
std::string json_body = resp.dump();
std::string response =
"HTTP/1.1 200 OK\r\n"
"Content-Type: application/json\r\n"
"Content-Length: " + std::to_string(json_body.size()) + "\r\n"
"\r\n" + json_body;
send(client_fd, response.c_str(), response.size(), 0);
close(client_fd);
return;
}
close(client_fd);
}
handleMetrics(): calculates metrics using a latency vector that is stored inSchedulerclass.
// handle GET /metrics
void handleMetrics(int client_fd) {
std::lock_guard<std::mutex> lock(sch.m);
std::vector<float> sorted = sch.latencies;
std::sort(sorted.begin(), sorted.end());
float p99 = 0.0f;
if (!sorted.empty()) {
p99 = sorted[(int) (0.99 * (sorted.size() - 1))];
}
nlohmann::json j;
j["p99_latency_ms"] = p99;
std::string body = j.dump();
std::string response =
"HTTP/1.1 200 OK\r\n"
"Content-Type: application/json\r\n"
"Content-Length: " + std::to_string(body.size()) + "\r\n"
"\r\n" + body;
send(client_fd, response.c_str(), response.size(), 0);
close(client_fd);
}
That’s it for the server code.
main.cpp
This file just puts everything together and we run this file to check the results.
#include "llama.h"
#include "scheduler.hxx"
#include "worker.hxx"
#include "http.hxx"
#include "job.hxx"
#define MODEL_PATH "/home/imaayush/code/Forge/Forge/Llama-3.2-1B-Instruct-Q4_K_M.gguf" // path to your GGUF model file
int main() {
llama_model_params mparas = llama_model_default_params();
llama_model* model = llama_model_load_from_file(MODEL_PATH, mparas);
Scheduler sch;
Server server(8080, sch, model);
server.start();
}
observations and improvements
This system was primarily built to learn the language and understand systems like Ollama.
No AI was used to write code. Every line is hand-written or taken from documentation (like the llama.cpp code), which might as well be a flex nowadays.
improvements
This systems poses a lot of scope for improvement. It gives a p99s of ~7 seconds. And it’s majorly because the model takes appx 7 seconds to finish a response so the threads wait there for the inference to get over before sending the response back to client.
Below are some things that I know on the top of my head that could be bottleneck:
- latency calculation: in forge, i use a vector in the scheduler class that manually adds each reponse’s endTime - startTime to caculate the p99. What if the number of requests increase? And goes above a million requests? On top of that, for p99s calculation we’re also sorting the whole vector which is O(NlogN). There’s our bottleneck 1.
- aging_loop: right now, what aging_loop does is, after one second, it pulls out EACH job from the queue and updates the currPriority and puts the whole thing back. This will be horrendous when the requests are above say 1000.
- this whole thing will end up in an OOM error if there are more than 5000 requests because we will have to create 5000 threads for all the requests and then make them wait for the response from the worker threads.
- We’re using a fixed
bufof 4096 bytes for recieving the response from server. If it can’t hold that much response gets trucated.
Overall, the load balacing is not optimal, which honestly is okay for now. I plan to work on this more and fix these soon.
This was a VERY interesting project to do! Hopefully you get values out of this.
This marks the end of me trying to learn servers.
all the code is: https://github.com/aayushyatiwari/Forge-inference_server
As always, thank you for reading.
~ Aayushya
References
cpp reference official doc
https://blog.andreiavram.ro/job-scheduler-cpp/
my code: https://github.com/aayushyatiwari/Forge-inference_server
llama.cpp backend: https://github.com/ggml-org/llama.cpp/blob/master/examples/simple/simple.cpp